코플잇 아키텍쳐 구성 중 삽질 회고….
scenario
코플잇의 관리자를 생각해보자. 관리자는 유저가 풀어야할 과제의 기본 코드와 테스트케이스를 계속해서 업데이트 한다. 이 관리자가 새로운 문제를 만들고자 할 때, 로컬에서 자기 스스로 코드를 돌려보고 테스트케이스를 통과 시켜보는 과정이 필요하다. 로컬에서의 작업을 끝낸 후 실제 서비스에 적용되는 데이터를 업데이트 하려면 어떻게 해야할까?
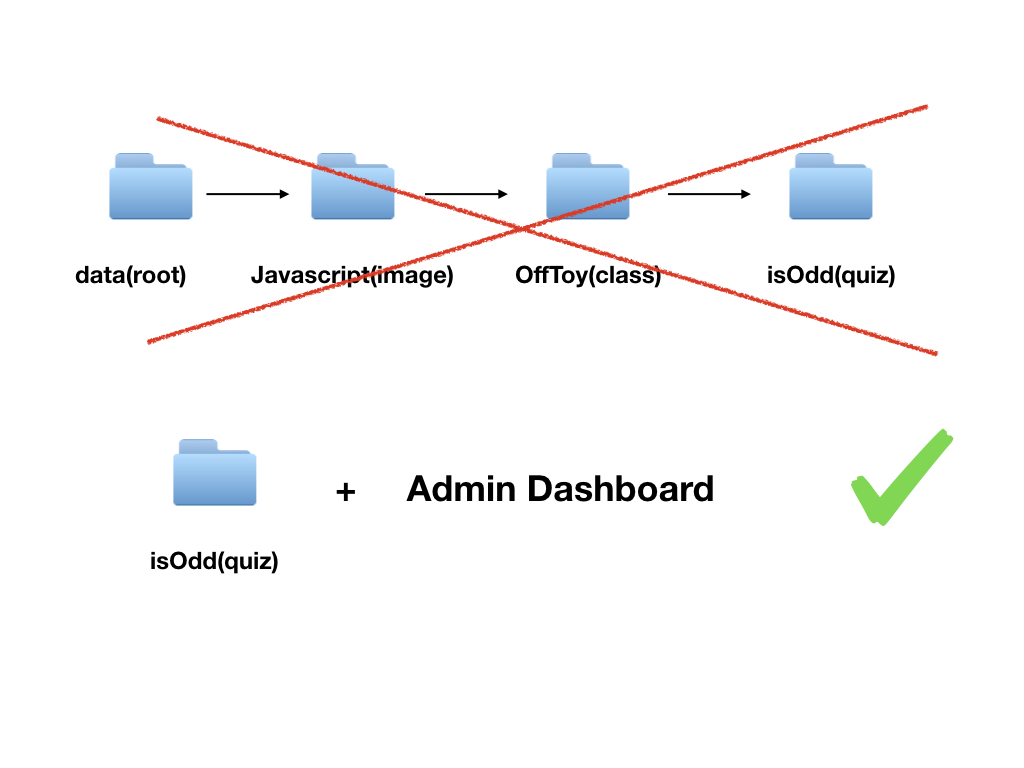
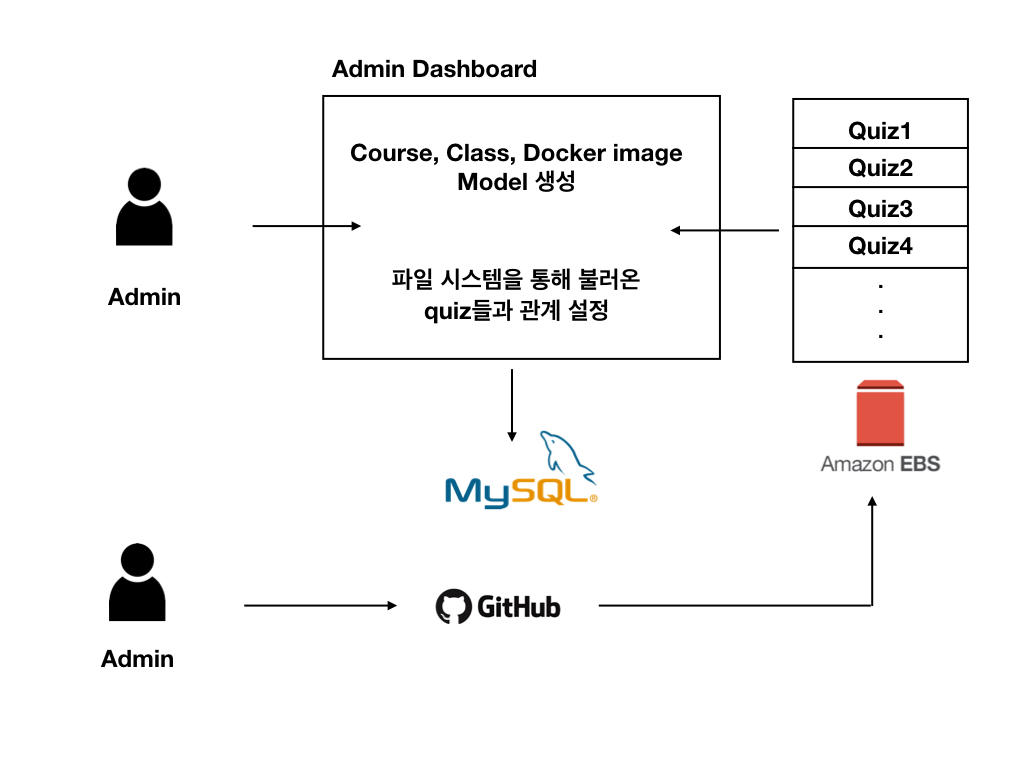
가장 단순한 방법으로는 아래와 같이 코드를 가져다가 붙여 넣어 관리자 페이지를 이용해 업데이트 할 수 있을 것이다.

하지만.. 위 방법은 너무 번거로워 보였다… 로컬에서 작업 후에 git commit / push만으로 데이터를 업데이트 할 수 있다면 정말 편하지 않을까?
그래서 만들어진 아래의 아키텍쳐
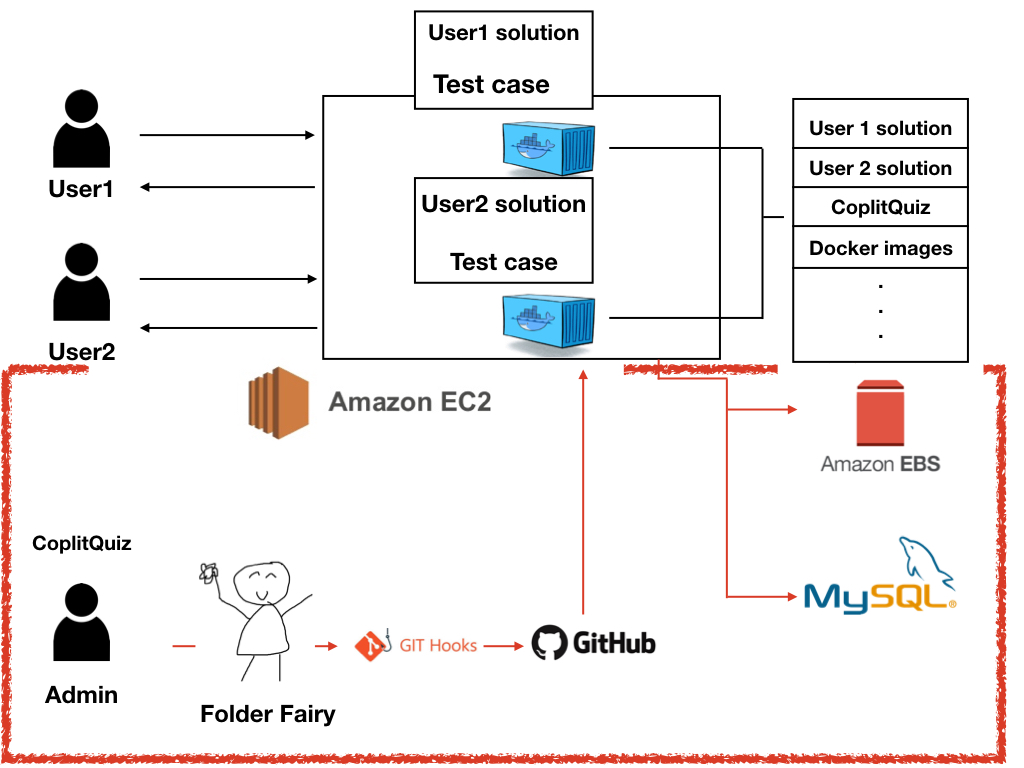
단순히 흐름만 보면,
- 로컬에서 Folder Fairy 와 Git hooks를 통과 후 작업한 파일(코딩 문제, 테스트케이스)이 Github로 올라가게 된다.
- Github에 걸어놓은 webhook이 실행돼서 커밋내용을 담은 payload를 우리 서버로 보내준다.
- payload를 받은 서버는 commit내용을 분석하여 데이터베이스에 반영하고, Github에 올려진 파일들을 EBS에 pull 받게 된다.
- 필요시에 file system을 이용해서 EBS에서 필요한 데이터를 가져와 쓴다.
첫 번째 Issue
관리자가 만든 수강생들이 풀어야할 문제와 Testcase들은 Local -> github -> EBS 로 흘러가 파일시스템을 이용해 가져다 쓸 수 있다. 여기서 단순히 추가/삭제/업데이트만 할거라면 파일시스템으로도 충분하다. 하지만 어떤 유저가 어떤 문제를 풀었는지, 어떤 문제가 어떤 코스에 포함되는지 등 데이터간에 관계가 필요하기 때문에 RDBS의 사용은 피할 수가 없다. 로컬에서 작업한 파일들을 어떻게 데이터베이스에 반영 할 수 있을까?
2번, 3번 과정을 살펴보자.
Github에서 보내주는 payload는 우리가 커밋했던 내용을 보내준다.

이 커밋내용을 데이터베이스에 그대로 반영하기 위해 로컬에서 작업하는 파일의 폴더구조에 어떤 약속을 심어놨다.
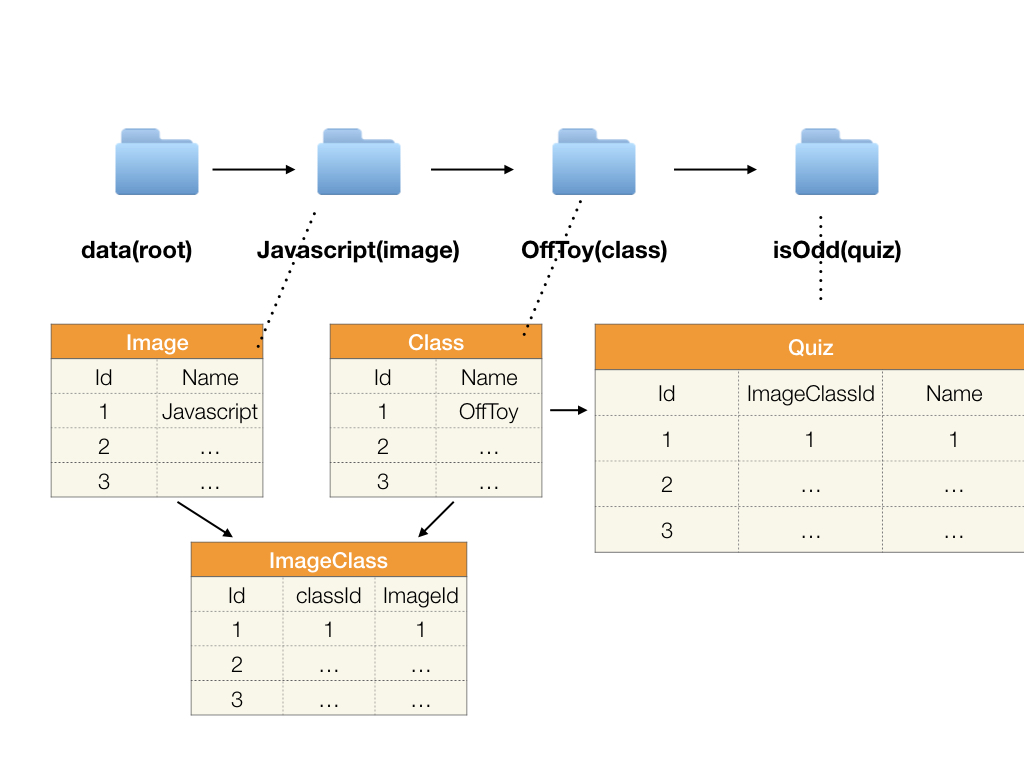
이런 형태로 데이터베이스에 있는 테이블 간의 관계에 따라 폴더 구조를 그대로 구현하였다.
3번 과정에서 ‘commit 내용을 분석해서 데이터베이스에 반영하고’ 라고 되어있다. 이를 예를 들면,
payload 이미지 아래쪽에 added를 보면 data/node/IAT/dk/index.js 파일이 추가 된 것을 알 수 있다.
그러면 정해진 약속에 따라, DockerImage 테이블에 node 라는 데이터, classRoom 테이블에 IAT라는 데이터, Quiz라는 테이블에 dk라는 데이터. . . 이런식으로 어떤 파일이 로컬에서 업데이트 되었는지를 분석해서 데이터베이스에 그대로 반영할 수 있다.
두 번째 Issue
인간은 실수를 반복하는 동물이다. 위의 방식대로 했을 때 안정성이 보장 될까?
가령, 로컬에서 약속과 다른 폴더구조를 보내온다면 데이터베이스에 엉뚱한 데이터가 반영될 가능성이 엄청나게 커진다. 어떻게 안정성을 보장하지?
1번 과정을 보면 ‘로컬에서 Folder Fairy 와 Git hooks를 통과 후’ 라고 돼있다.
Folder Fairy?
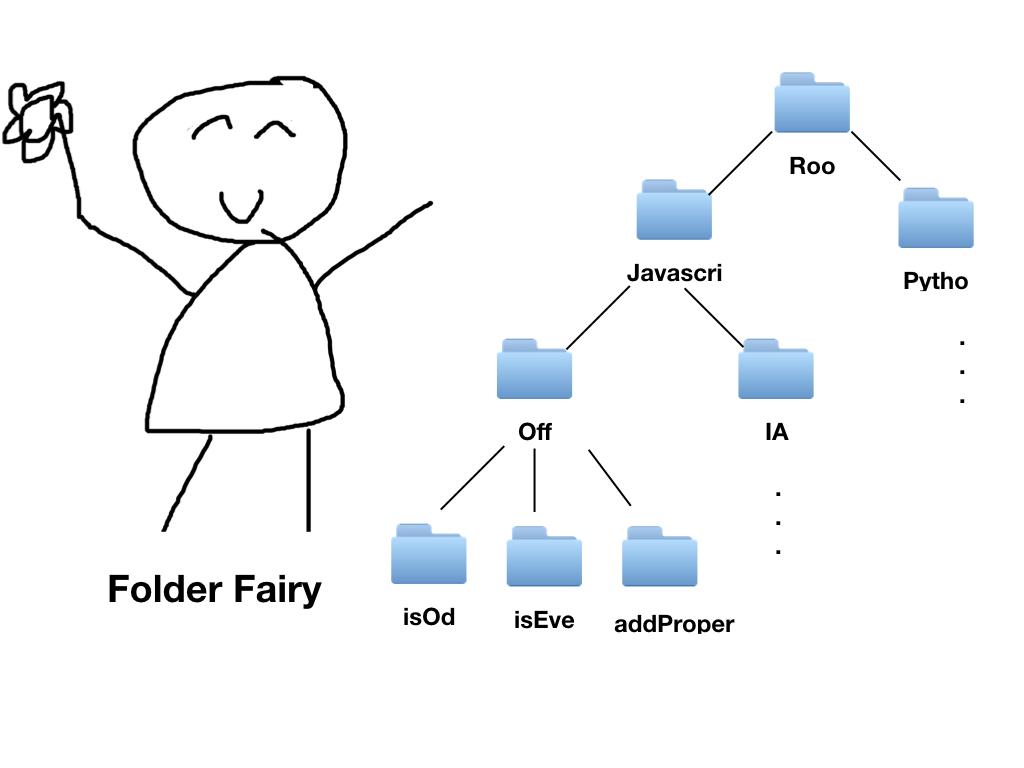
일명 폴더요정은, 내가 만든 작은 라이브러리다. 인간의 손을 타지 않고 프로그램으로 약속된 폴더구조와 기본 파일들을 생성하기 위해 만들었다.
폴더 요정을 사용하면 자동으로 필요한 폴더와 파일들을 생성해주고, 모든 폴더들을 Tree 구조를 이용해 관리하게 된다. 그리고 깊이우선탐색을 통해 손쉽게 탐색 할 수 있어, 엄격한 폴더구조를 위해 여러가지 검사를 진행 할 수 있다.
예를 들면, 동일한 문제의 이름이 존재하는지, 필요한 파일이 제대로 존재하는지 등 약속된 폴더구조를 형성하고 있는지 판단할 수 있게된다.
Git hooks에 이 검사 로직들을 적절하게 넣어 commit이나 push 전에 판단해, 엉뚱한 폴더구조가 서버로 날라가는 것을 사전에 방지한다.
transaction

여기에 더해 온전한 트랜잭션이 이뤄지도록 스크립트파일을 서버에 추가했다. 데이터 관리가 Github와 Database, 양쪽에서 이뤄지고 있는데 어느 한 곳만 업데이트되지 않도록 막기 위함이다.
예를 들면, EBS로 git pull이 실패했다면 데이터베이스도 업데이트 하지 말고 실패했다는 메일을 자동으로 보내도록, Git pull은 성공했는데 데이터베이스 반영이 실패했다면 Git reset후 메일을 자동으로 보내도록 하는 식으로 로직을 구현하였다.
그런데 망했다!?
뭔가 열심히 한 거 같은데 왜 망했을까?
여전히 존재하는 안정성 문제

그렇다. 지금 까지 보였고, 생각났던 모든 위험은 사라졌다. 그리고 실제로, 현재 동작하는데 아무런 문제가 없다. 하지만 언제 쳐맞을 지 모르는게 문제다.
굳이 쳐맞지 않아도 될 것을…
확장성은 정말 노답
의존성이 너무 높다.
이 서비스가 언제, 어떤식으로 확장이 될지 모르겠지만, 만약 데이터베이스를 고쳐야한다면?
폴더 구조도 고쳐야하고…
github payload 분석 로직도 고쳐야하고…
폴더 요정도 고쳐야하고…
어떻게 해야할까?
욕심을 버리면 되지 않을까 싶다.
사실, 모든 것을 로컬로 끝내려고 해서 벌어진 문제라고 생각한다. 로컬에서의 작업이 필수불가결한 데이터만 File형태로 보관하고, 그 외 모든 데이터는 관리자 페이지를 이용해 model을 생성해서 관리하게 된다면 확장성에 숨통이 마아아않이 트일 거 같다.